Postgres Schema for a Multi-Tenant Ledger: The Trade-offs No One Talks About
Your bank balance is not a number someone saved, it's a question the database answers by adding up your whole history, and that one design choice decides almost everything else
WhoAmI => notes.sohag.pro/author
Open your banking app and look at the balance. It feels like a saved number, a single field in a row somewhere with your name on it, that goes up when money arrives and down when it leaves. That mental model is wrong, and the gap between that model and how a real ledger works is most of what Week 3 was about.
In a proper ledger your balance is not stored anywhere. It is computed, every time, by adding up every entry that ever touched your account. The history is the truth. The balance is just a question you ask of that history. Last week I built the double-entry domain model in Go types. This week I had to put it on disk, in Postgres, in a way that keeps that property honest. This is post 3 of 12.
The one decision that shapes the rest
Here is the fork in the road. When someone posts a transaction, you can do one of two things with their balance.
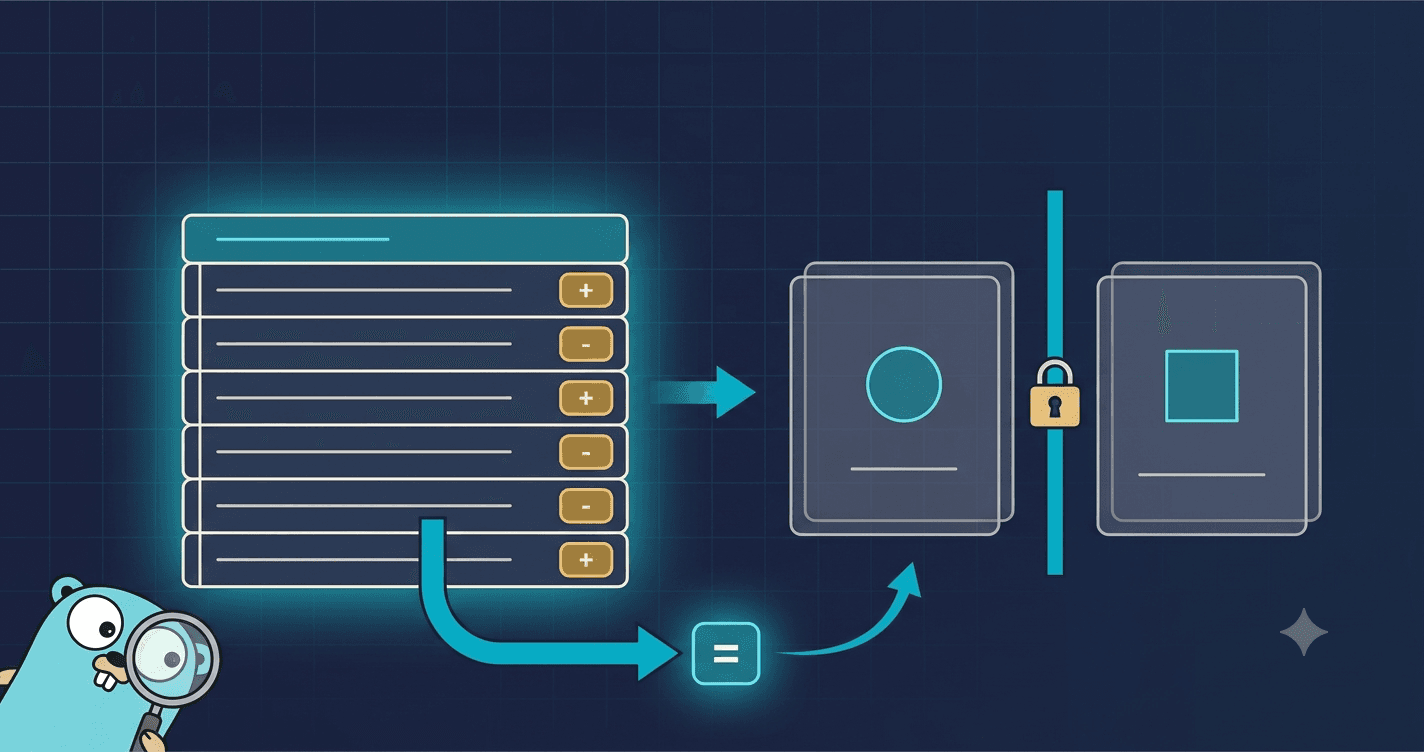
Option A: keep a balance column. Each account row has a balance field. Every posting reads it, adds the amount, and writes it back. Reads are trivial, one column lookup.
Option B: keep only the postings. Postings are append-only rows. The balance is SUM(amount) over an account. Nothing is ever updated in place.
Option A is faster to read and it is the one most people reach for first. It is also the exact bug double-entry exists to prevent. The moment you store a balance, you have two copies of the truth: the number in the column, and the sum of the postings. The day those two disagree, and they will, after a crash mid-write, a missed update, a racy retry, you have no way to tell which one is right. Money is now ambiguous, which in a ledger is the worst thing money can be.
So go-ledger uses Option B. Postings are append-only. Balances are derived. There is exactly one source of truth, and it cannot drift from itself.
Picture my dinner debt from post 1, the 600 taka I owed a friend, now sitting in the actual tables:
postings table (the only truth)
+------------+--------------+---------+
| account | txn | amount |
+------------+--------------+---------+
| sohag | dinner-debt | -600 |
| friend | dinner-debt | +600 |
+------------+--------------+---------+
| |
| SUM(amount) | SUM(amount)
| WHERE account=sohag | WHERE account=friend
v v
balance: -600 balance: +600
No balance column anywhere. Ask the question, get the answer.
The trade is real and worth saying out loud: reads are now an aggregate, not a lookup. At v1 scale that is a non-issue. If it ever bites, the fix is a cached rollup that is rebuilt from the postings, never a mutable primary balance. The history stays sacred.
Three tables, not five
My build plan listed five tables for this week: accounts, transactions, postings, idempotency_keys, and audit_log. I built three.
The last two belong to Week 6. I do not know their columns yet, because I have not written the code that uses them. Designing a table before its consumer exists just means I get to ALTER it later anyway, so there is no real saving in rushing it. Migrations are cheap and ordered. Each table arrives with the feature that needs it. That is the whole argument, and it is the kind of small discipline that keeps a twelve-week project from quietly turning into a thirty-week one.
So 0001_initial.sql creates accounts, transactions, and postings. That is it.
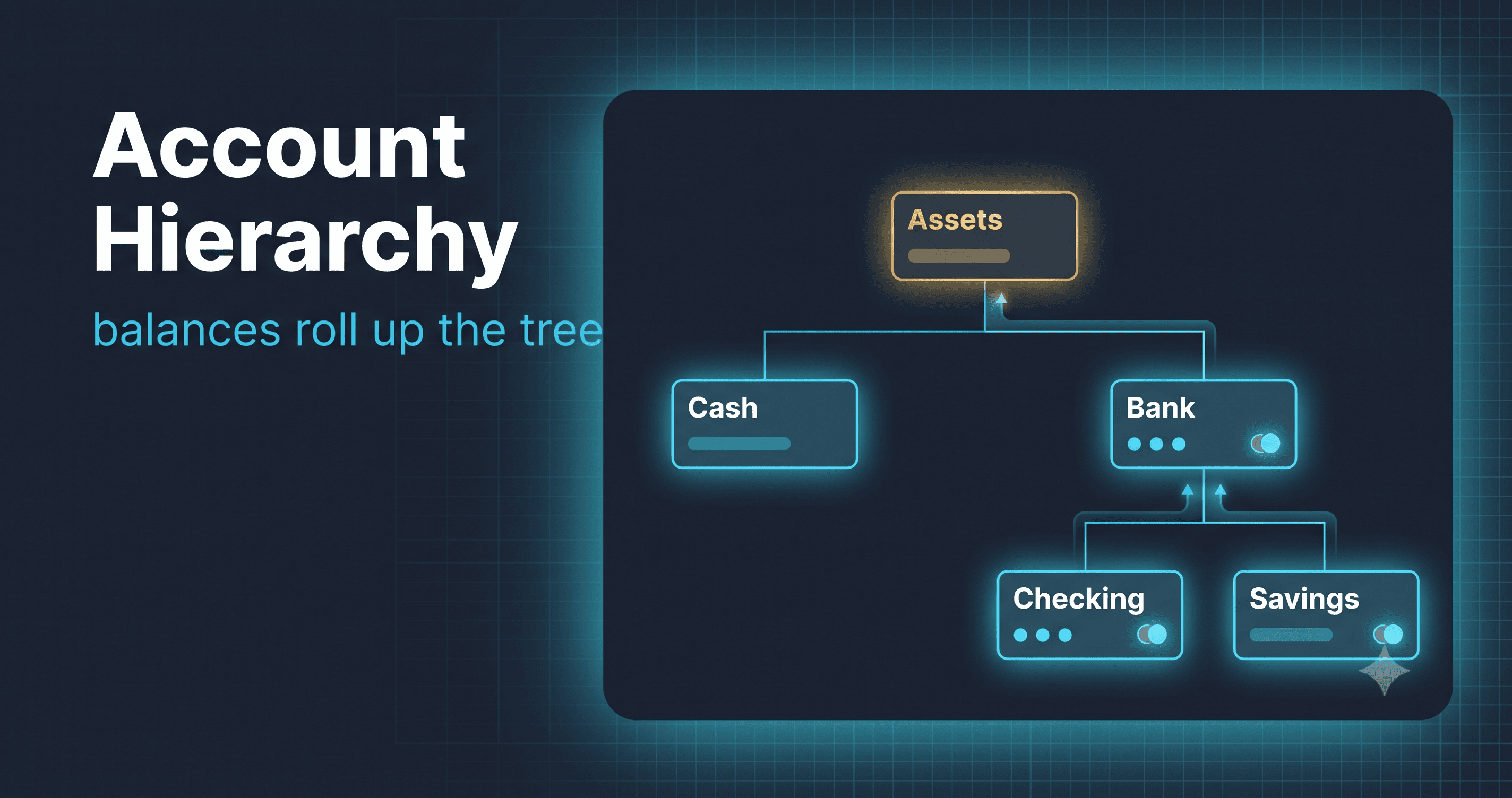
Multi-tenant from the first migration
The blog title says multi-tenant, and that is the part most schema posts skip. A real ledger does not hold one person's accounts. It holds many independent tenants' books in the same database, and tenant A must never, under any bug, see tenant B's money.
There is no login or auth in go-ledger yet. So why is there a tenant_id on every single table already? Because adding it later is the migration nobody wants to write. Retrofitting tenancy onto a populated ledger means a new column, a backfill across every row, and rebuilt foreign keys, all on live data. Adding the column now, while the tables are empty, costs nothing. The column goes in on day one even though the code that resolves a tenant comes much later.
But a column is just a label. The interesting part is making the database itself refuse to mix tenants. Here is the trick:
accounts transactions
+-----------------------+ +-----------------------+
| id (uuid) | | id (uuid) |
| tenant_id (uuid) | | tenant_id (uuid) |
| ... | | ... |
| UNIQUE (tenant_id,id) | | UNIQUE (tenant_id,id) |
+-----------------------+ +-----------------------+
^ ^
| FK (tenant_id, account_id) | FK (tenant_id, transaction_id)
| |
+---------------------------------------+
| postings |
| tenant_id, account_id, transaction_id|
+---------------------------------------+
A posting must match its account's tenant AND its transaction's tenant.
A cross-tenant posting is not "discouraged". It is impossible to insert.
Instead of a plain foreign key on id, accounts and transactions carry a UNIQUE (tenant_id, id), and postings reference the pair. Now Postgres will reject a posting that points at an account in a different tenant. Tenant isolation stops being a thing every query has to remember and becomes a guarantee the database enforces. The query that forgets its WHERE tenant_id = ? is still a bug, but the catastrophic version, a posting that silently links two tenants' books, simply cannot be written.
The small choices that add up
A few smaller decisions, each with a fork worth a sentence:
UUIDv7 keys, generated in Go. Keys are UUIDs, not auto-incrementing integers, and the app generates them before insert using UUIDv7. Version 7 is time-ordered, so it keeps the nice index locality that makes serial keys fast, while staying globally unique and not coupled to the database. Generating them in Go means the caller knows the ID without a round-trip, and tests are deterministic. The cost is 16 bytes instead of 8. Worth it.
Currency on the transaction, not the posting. The domain already guarantees every posting in a transaction shares one currency. So I store the currency once, on the transaction, and a posting stays a single signed integer amount. Less duplication, and the single-currency rule is visible in the shape of the data.
Account type as text with a CHECK, not a Postgres enum. A column constrained by CHECK (type IN ('asset','liability', ...)) reads fine in plain SQL, and adding a type later is an ordinary migration instead of the awkward ALTER TYPE dance an enum forces. Low churn, so the enum's only real benefit does not apply.
No balance CHECK yet. The rule that a transaction's postings must sum to zero lives in the Go domain for now, in Transaction.Validate(). The database-level constraint that makes it impossible regardless of caller is deliberately Week 4 work, landing with the concurrency handling where it belongs. I am being honest about that gap rather than pretending the schema is already bulletproof.
Proving it works against a real Postgres
A schema you have not run is a guess. The Week 3 definition of done was a single integration test that exercises the whole happy path end to end, against a real Postgres, not a mock.
The test uses testcontainers-go to spin up an actual postgres:16-alpine in a container, runs the migration with goose, then does the real thing: create two accounts, post a balanced two-leg transaction, read both balances back, and assert they are +10000 and -10000 and that they net to zero. That last assertion is the whole point of the project, checked end to end:
cashBal, _ := repo.Balance(ctx, tenant, cash.ID) // +10000
revBal, _ := repo.Balance(ctx, tenant, revenue.ID) // -10000
if cashBal.Amount()+revBal.Amount() != 0 {
t.Errorf("ledger does not net to zero")
}
There is a second test that creates an account under one tenant and tries to read it as another tenant, expecting "not found". The isolation I designed into the foreign keys is not just a claim in this post, it is a test that fails if I ever break it.
One honest detail: the test skips, rather than fails, when no Docker daemon is reachable, so a teammate without Docker still gets a green make test. The risk is that a skip can hide a broken integration path, so CI runs Docker and exercises the real thing for real. On my own laptop that meant getting a container runtime going (I use colima, not Docker Desktop), watching the first run pull the Postgres image, and finally seeing three green PASS lines against a live database. That is the moment the schema stopped being a guess.
The AI companion, week 3
The running subplot of this series is that I build this with Claude Code as a pair, and I stay honest about the split. This week Claude wrote a lot of the mechanical surface: the migration SQL, the sqlc setup, the repository adapter, the integration test. But the decisions in this post, append-only over a balance column, tenant_id on day one, composite foreign keys for isolation, three tables not five, are mine, argued out before any code got written and recorded in ADR-003. The deal holds: Claude accelerates the typing, I own the why. A ledger I could not explain line by line would defeat the point.
Where this leaves us
The ledger now has a home on disk that cannot lie to itself. Balances are derived, postings are immutable, tenants are isolated by the database, and there is a test that runs the whole path against real Postgres and proves it.
What is missing is the hard part: what happens when two requests post to the same account at the same time. Right now the balance invariant is enforced in Go, optimistically, with nothing stopping two concurrent writers from racing. Next week is atomicity and concurrency: wrapping posting in a database transaction at SERIALIZABLE isolation, adding the database-level CHECK that makes an unbalanced transaction impossible, and then pointing 10,000 concurrent posts at the same accounts to see if the invariant holds. That is where ledgers get genuinely interesting.
The repo is open source at github.com/sohag-pro/go-ledger. Follow along or steal the schema.