Designing a REST API for a Payment Ledger: Resources, Verbs, and Why I Avoided GraphQL
The running-balance line in your banking app looks like a stored number, but building it taught me more about pagination and window functions than any tutorial ever did
WhoAmI => notes.sohag.pro/author
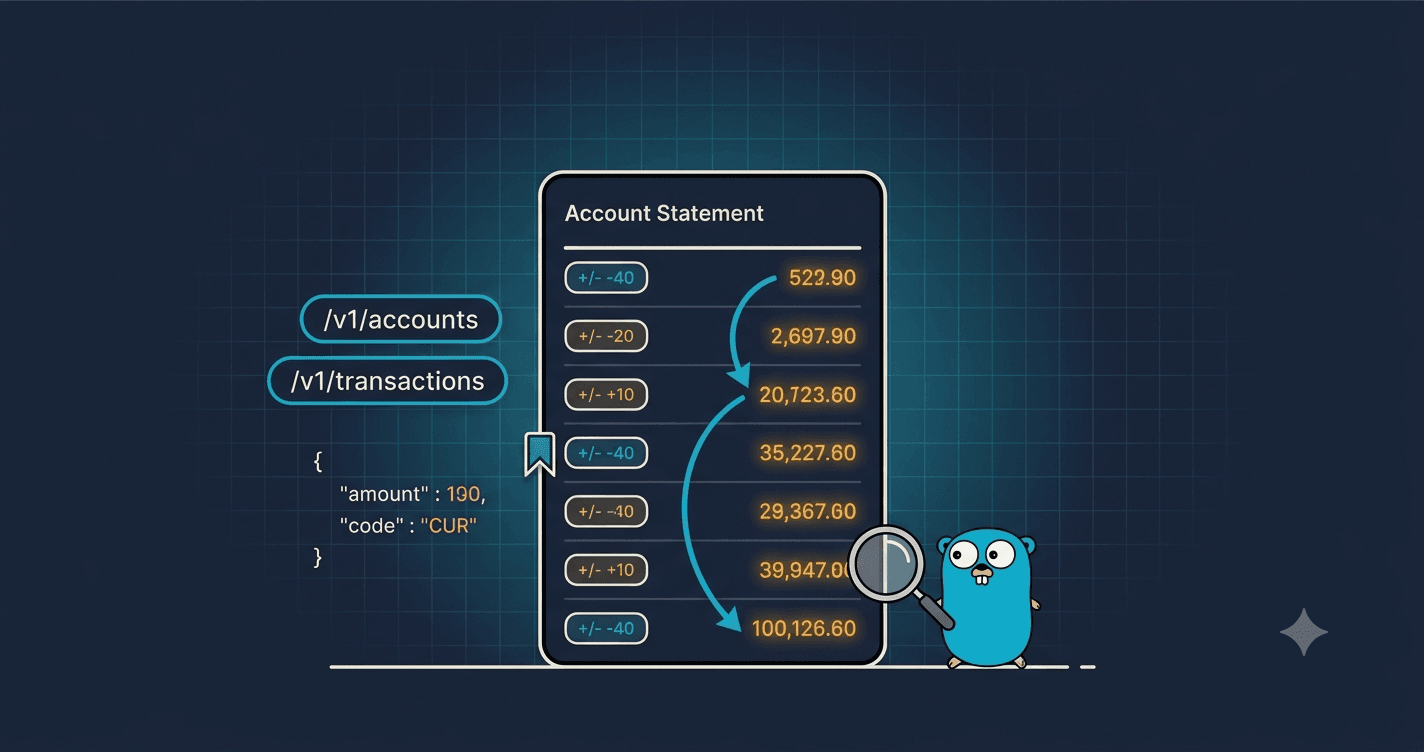
Open your banking app and scroll the statement. Every row has a little running balance on the right: after this coffee you had 4,210, after that salary you had 54,210, and so on down the list. It feels like each of those numbers was saved next to the transaction when it happened. It was not. That number does not exist anywhere until you ask for it, and producing it correctly, in pages, fast, turned out to be the most interesting thing I built this week.
For four weeks go-ledger has been a thing that only its own tests could talk to. This week I gave it a REST API and put it online. As of now you can actually curl it at go.sohag.pro. This is post 5 of 12.
Resources and verbs, not remote procedures
A ledger has a small, sharp set of nouns: accounts and transactions. So the API is boring in the good way, just those resources and the standard verbs:
POST /v1/accounts create an account
GET /v1/accounts/{id} read one
GET /v1/accounts/{id}/balance its current balance
GET /v1/accounts/{id}/statement its postings, with running balance
POST /v1/transactions post a balanced transaction
GET /v1/transactions/{id} read one
People sometimes ask why not GraphQL, since it is the fashionable default for a new API. GraphQL earns its keep when clients need to shape wildly different views over a big, interconnected graph, and when over-fetching is a real problem. A ledger is the opposite of that. The resource set is tiny and well defined, the relationships are obvious, and the queries that matter ("what is this account's balance", "show me this account's statement") are known up front. GraphQL would buy me a flexible query language I do not need and hand me N+1 queries and caching headaches I would rather not have. REST over JSON maps cleanly onto these resources, it is curlable and cacheable, and everyone already understands it. gRPC is still coming later for internal service-to-service calls, sharing the same core, but the public front door is REST.
Money on the wire
Here is the first decision that matters for a payment API: how does an amount look in JSON? go-ledger sends money as a signed integer count of the smallest unit, plus a currency code:
{ "amount": 10000, "currency": "USD" }
That is 100.00 dollars, as 10,000 cents. No decimal point, no floating point, no string parsing at the edge. It maps one to one onto the int64 the ledger uses internally, so the API is exactly as precise as the ledger is. This is the same choice Stripe and most payment APIs make, and for the same reason: the moment you let 100.00 become a float somewhere, you have invited rounding error into a place where money lives. A debit posting is a positive amount, a credit is negative, and a transaction's postings still have to sum to zero. Posting that coffee sale looks like this:
POST /v1/transactions
{
"currency": "USD",
"postings": [
{ "account_id": "...cash...", "amount": 450, "description": "latte" },
{ "account_id": "...revenue...", "amount": -450, "description": "latte" }
]
}
Two legs, plus 450 and minus 450, summing to zero. The API hands the request to the same domain code and the same database triggers from the earlier weeks, so all the invariants still hold. The HTTP layer is thin on purpose: it translates JSON to domain types, calls a service, and maps any error to a clean status code. An unbalanced transaction comes back as a 422, a missing account as a 404, a write conflict as a 503, all as RFC 7807 problem+json.
The statement, and the number that is not stored
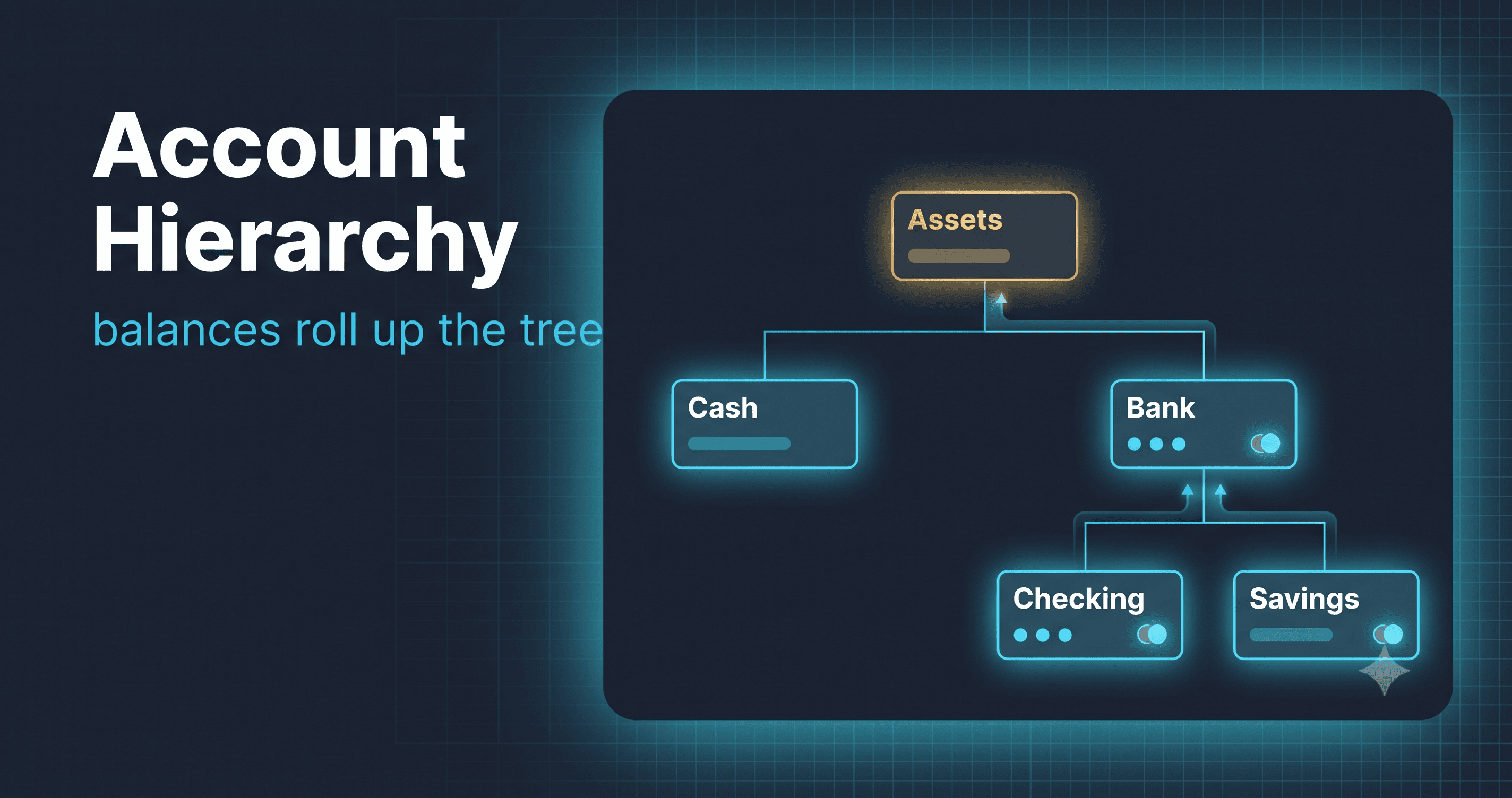
Back to that running balance. A statement is a list of the postings that touched one account, newest first, and next to each one, the balance of the account as of that posting. Remember the rule from week 3: balances are never stored, they are summed from the postings. So the running balance on row N is the sum of every posting up to and including row N.
postings for "Cash", oldest to newest running balance
+-------------------------------+ (cumulative sum)
| +5000 opening float | -----> 5000
| -450 latte | -----> 4550
| +1200 pastry sale | -----> 5750
| -450 latte | -----> 5300
+-------------------------------+
the statement shows these newest first,
each carrying its own running total
In SQL, that running total is a window function: SUM(amount) OVER (ORDER BY created_at, id). It sums the postings in order, carrying the total forward row by row. Easy enough, until you remember the statement is paginated. A page shows maybe 50 rows out of an account's thousands. If I compute the window over just the 50 rows on the page, the running balances are wrong, they restart from that page instead of from the beginning of the account's history. The window has to see the whole history even when I only return a slice of it. So the query computes the running balance over all of the account's postings first, then slices out one page.
That is honestly expensive: each page scans the account's full history to rebuild the running totals, because I refuse to store a balance anywhere (storing one is exactly the drift bug double-entry exists to prevent). At this project's scale it is a non-issue, and the index from week 4 makes the scan a tight range. If it ever becomes a problem, the fix is a cached rollup rebuilt from the postings, never a mutable stored balance. The history stays the only truth.
Paging without lying to the user
The other half of statements is how you ask for the next page. The obvious way is "limit 50, offset 50, offset 100", and it is also subtly broken. If someone posts a new transaction while you are paging, every offset shifts by one, and you either see a row twice or miss one entirely. For a bank statement, silently skipping a line is not a great look.
So go-ledger uses keyset pagination. Instead of "skip 50 rows", each page hands back an opaque cursor that points at the exact last row it showed, and the next page asks for "everything older than this row":
page 1: newest ... down to row X -> cursor = position of row X
page 2: everything strictly older than row X -> cursor = row Y
page 3: ...older than row Y... -> no more rows, cursor = null
The cursor is the row's (created_at, id) pair, base64-encoded so the client treats it as opaque. Because it anchors on a real row rather than a count, new inserts at the top do not shift anything underneath you. Pages stay stable. When a page comes back shorter than the limit, that is the end, and the response says next_cursor: null.
When the query generator pushed back
A small war story. I write SQL by hand and use sqlc to generate type-safe Go from it. My first version of the statement query put the window function in a subquery and used a tuple comparison, (created_at, id) < (cursor), for the keyset. Postgres is perfectly happy with that. sqlc was not: its analyzer could not resolve the subquery alias and refused to generate. I tried expanding the comparison out longhand. Still no. What finally worked was moving the window into a CTE (a WITH block) with plain unqualified columns.
The lesson stuck with me: sqlc has its own SQL analyzer, separate from Postgres, and a query the database accepts can still need restructuring for the generator to understand it. That is the tax for type-safe queries with no ORM in the middle, and I will pay it, but it is worth knowing the tax exists. I cover the actual behavior with an integration test against a real Postgres, because sqlc only proves it can parse and type the query, not that it returns the right rows.
The docs cannot drift
One thing I am quietly proud of: I never write the OpenAPI spec by hand. The API is built with huma, where each endpoint is a typed Go function, and the spec is generated from those same functions. There is a test that fails the build if the committed spec does not match what the handlers produce. So the interactive docs at /playground and the spec at /openapi.json are always exactly the running API, not a hopeful description of it that rots over time. Adding an endpoint and forgetting to document it is not possible here, the test catches it.
It is real now
The quiet milestone this week is that go-ledger stopped being a test suite. For four weeks the server ran with no database at all, deliberately, because nothing it served needed one. This week the endpoints need real persistence, so the server now connects to Postgres, runs its own migrations on startup, and refuses to boot without a database, because a ledger API with no ledger behind it should not pretend to work.
That also meant standing up Postgres on the actual server for the first time: a native install, a dedicated database and user listening only on localhost, tuned down to fit a 1 GB box, with a nightly backup. Then I pushed, the pipeline built and deployed, and a few seconds later I created an account and posted a transaction against the live API and watched the balance come back correct. The thing works in the world now, not just on my laptop.
The AI companion, week 5
Same arrangement as every week: I build this with Claude as a pair and stay honest about the split. This week it wrote a lot of the mechanical surface, the handler structs, the error mapping, the fake repository for the HTTP tests, and it was genuinely useful when sqlc started rejecting my query, working through the CTE rewrite with me. The shape of the API, the choice to avoid GraphQL, money as integer minor units, keyset over offset, the decision to keep balances derived even when it makes statements more expensive, those were mine, argued out and written down in ADR-006. The deal holds: it accelerates, I decide and understand.
Where this leaves us
The ledger has a front door now. You can create accounts, post transactions, read balances, and pull a paginated statement with a running balance, all over a clean REST API with generated docs, live on the internet.
What it does not have yet is safety against the thing that haunts every payment API: the retry. A client posts a payment, the network drops the response, the client retries, and now you have charged someone twice. Next week is idempotency keys and an immutable audit log, the two patterns that make a payments API boringly safe to call. That is where this gets properly fintech.
The repo is open source at github.com/sohag-pro/go-ledger. Go curl it, or go read why your favorite API uses keyset pagination and never told you.